텍스트 분석 기초
🔶 텍스트 마이닝(=자연어처리) (Natural language processing)
◻ 개념 :
- 사람이 사용하는 일상의 말이나 언어의 의미르 분석해서 컴퓨터가 처리할수록 하는 작업\
- 텍스트에서 컴퓨터가 이해 할 수 있는 특성으로 추출하는 작업
🔶자연어 처리과정
![[Screenshot_407.png]]

◻ 0. 전처리
- 오류수정, 결측치처리 등등 (자세한건 아래에서 확인)
◻ 1. 토큰화 - 큰 문장을 작은 문장 또는 단어로 분리하는 작업
- 문장 분할 및 형태소 분류
◻ 2. 인코딩 - AI모델이 숫자를 기반으로 하기때문에 문자 데이터를 수치형으로 변환하는 작업
- 모델이 이해할수있게 문자를 숫자로 변환
◻ 3. 임베딩 - 단어간의 관계(상관성)를 분석해서 컴퓨터가 중요도를 판단하여 이해할수 있게 단어사전으로 만드는작업
- 의미를 부여하여 단어사전 생성
🔶0. 텍스트 전처리 작업
◻ 오류수정(정제 : cleaning)
◻ 결측치처리
- 삭제 혹은 부정표현으로 채우기
◻ 정규화
- 정규식 사용해서 필요한 내용만 추출
- 예) 한글분류시 영문,숫자등을 제거
◻ 어간 추출
![[Screenshot_405 1.png]]
- 단어에서 중요한 부분만 추출 (일반적으로 앞쪽에 위치)
- 예 ) 만들었어요,만들고,만들다,만듦 ----> 만들다
◻ 표제어 추출
- 대표 단어를 추출
- 예 ) 먹었어요,드셨어요,식사했어요,맛을봤어요 -> 먹다
◻ 불용어 (stopwords)
- 학습에 사용하지 않을 단어
◻ 텍스트 증식(증강)
- 텍스트데이터가 적은 경우 데이터의 수를 늘리는 작업
- 단어 삭제
- 예) 나는 학교에 갑니다 -> 학교에 갑니다
- 단어 교환
- 예) 나는 학교에 갑니다 -> 학교에 나는 갑니다
- 단어 추가
- 예) 나는 학교에 갑니다 -> 나는 버스로 학교에 갑니다
- 유사단어로 변경
- 예) 나는 학교에 갑니다 -> 나는 교실에 갑니다
- 번역기 사용후 재번역
- 예) 나는 학교에 갑니다 -> 我去学校 -> 저는 학교에 가요
- 단어 삭제
🔶1. 토큰화 처리과정
![[Screenshot_408.png]]
◻ 개념 : 문장(corpus)를 작은문장(chunk)이나 단어(token)로 분리하는 작업
◻ 영문 VS 한글 토큰화 차이
영문
- 빈공백으로 분리(띄어쓰기가 잘 진행되기 때문)
한글 - 토큰화가 어렵다
- 띄어쓰기가 잘 안되서 토큰화가 진행되기 어렵다.
- 꾸며주는 특성을 갖는 형용사/부사적 표현이 많다.
- 의태어/의성어 문제 (보글보글,지글지글 등)표현이 많다.
- 따라서 토큰화 대신 형태소 분리를 사용
◻ 형태소분리
◽ 형태소 분리 종류 : Kkma, Hanaum, Twitter,Okt
예시
text1 = "I am actively looking for Ph.D. students. and you are a Ph.D. student." text2 = "나는 버스를 타고 학교에 아침 일찍 갔습니다." print(word_tokenize(text1)) print(word_tokenize(text2))
결과
['I', 'am', 'actively', 'looking', 'for', 'Ph.D.', 'students', '.', 'and', 'you', 'are', 'a', 'Ph.D.', 'student', '.'] ['나는', '버스를', '타고', '학교에', '아침', '일찍', '갔습니다', '.']
◽ pos 사용하여 단어형태 분석
예시
okt.pos(text2)결과
[('나', 'Noun'), ('는', 'Josa'), ('버스', 'Noun'), ('를', 'Josa'), ('타고', 'Noun'), ('학교', 'Noun'), ('에', 'Josa'), ('아침', 'Noun'), ('일찍', 'Noun'), ('갔습니다', 'Verb'), ('.', 'Punctuation')]
◻ 정규화
◽ 개념 : 정규식을 이용해서 필요한 데이터만 따로 추출하는 작업
예시
corpus = "소크라테스가 말했습니다. '너 자신을 알라' ==> 무슨 의미 일까요? Now is 11 hour 35 minute. " result = re.compile("[^가-힣]") print(result.sub('',corpus))
결과
소크라테스가말했습니다너자신을알라무슨의미일까요해설
- ^ : not 의 의미
- 가-힣 : 한글전체
- ㄱ-ㅎ : 한글자음
- ㅏ-ㅣ : 한글모음
- A-Z : 영문 대문자
- a-z : 영문 소문자
- 0-9 : 숫자
◻ 표제어 추출
◽ 개념
- 대표단어 추출
- 해당 문장의 원형에 해당 단어를 추출
예시
#================================== # 표제어 추출 #================================== lemmatizer = WordNetLemmatizer() word = ['leaves','lives','dies','has','children'] print([lemmatizer.lemmatize(w) for w in word])
결과
['leaf', 'life', 'dy', 'ha', 'child']◻ 어간추출
◽ 개념 : 단어를 앞에서 잘라내서 추출
예시
#================================== # 어간 추출 #================================== s = PorterStemmer() print([s.stem(w) for w in word])
결과
['leav', 'live', 'die', 'ha', 'children']◻ 불용어
◽ 개념 : 학습에 사용하지 않을 단어를 미리 지정해서 필터링후 추출
예시
#================================== # 불용어 필터링 #================================== corpus = '고기를 아무렇게나 구울려고 하면 안 돼. 고기라고 다 같은게 아니거든. 예컨데 삼겹살을 구울때 중요한 게 있지.' result = [] # 불용어 목록 stop_words = ['은','는','이','가','을','를','하면','돼',',','.','라고','다','게','예컨데','\n'] # 형태소분리 result = okt.morphs(corpus,stem=True) print(result) # 불용어처리 result = [w for w in result if w not in stop_words] print(result)
결과
['고기', '를', '아무렇다', '구울', '려고', '하다', '안', '돼다', '.', '고기', '라고', '다', '같다', '아니다', '.', '예컨데', '삼겹살', '을', '구울', '때', '중요하다', '게', '있다', '.'] ['고기', '아무렇다', '구울', '려고', '하다', '안', '돼다', '고기', '같다', '아니다', '삼겹살', '구울', '때', '중요하다', '있다']
🔶2. 인코딩 처리과정
![[Screenshot_409.png]]
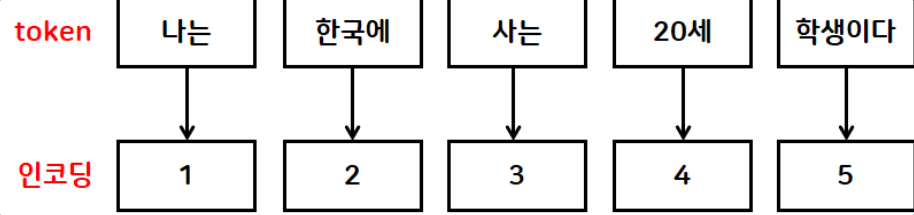
◻ 개념 : 학습을 위해 문자 데이터를 숫자 데이터로 변환하는 작업
◻ Tokenizer()
◽ 빈도수 기반 분석
◽ 빈도수 순으로 내림차순 정렬
- 빈도수가 동일하면 등장순 으로 정렬
◽ 정렬순으로 1부터 인덱스 부여
◽ 문자 토큰을 해당 인덱스로 변환
예시
# 토큰갯수 제한 tokenizer = Tokenizer(num_words=10) # 빈도분석 tokenizer.fit_on_texts(result) print(tokenizer.word_index) print(tokenizer.word_counts) # 인코딩 print(tokenizer.texts_to_sequences([result])) # 패딩 길이를 5로 설정 result = pad_sequences(en, maxlen=5, truncating='pre') print([result])
◽설명
num_words : 사용할 인덱스 의 개수
word_index : 인덱스분석
word_counts : 사용된 횟수 분석
texts_to_sequences : 토크나이징 결과 출력
pad_sequences : 훈련전 문장들의 길이를 맞추기 위해 임의로 0값을 집어넣는방식
![[Screenshot_410.png]]
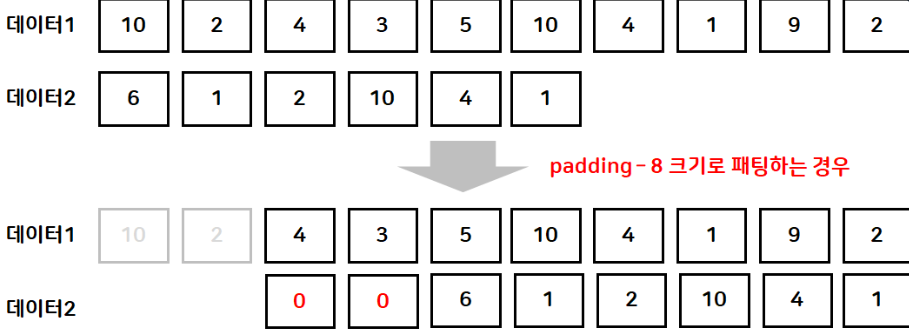
결과
[[1, 3, 2, 4, 5, 6, 7, 1, 8, 9, 2]] [array([[7, 1, 8, 9, 2]], dtype=int32)]
◽ BoW (Back of Word)
![[Screenshot_412.png]]

- 단어의순서를고려하지않고, 빈도수만 이용해서 텍스트를 수치화 하는 방법
- CountVectorizer와 TFI-DIF가 해당
◻ CountVectorizer()
◽ 빈도수기반
- 각 토큰별로 빈도수를 분석
- 각 토큰별로 빈도수의 수치로할당
◽ 원-핫 인코딩방식 (토큰의 수가 많아지면 크기가 커짐) - 같은길이로 만듦 -> 패딩 필요 없음
◽ 토큰을 사전순으로 오름차순정렬
◽ 정렬된 순으로 인덱스를 0부터 부여
예시
# countVectorizer from sklearn.feature_extraction.text import CountVectorizer okt = Okt() cv = CountVectorizer() cv_fit = cv.fit_transform([corpus]) print(cv_fit.toarray()) print(cv.vocabulary_)
결과
[[1 1 1 1 1 1 1 1 1 1 1 1]] {'고기를': 2, '아무렇게나': 7, '구울려고': 4, '하면': 11, '고기라고': 1, '같은게': 0, '아니거든': 6, '예컨데': 8, '삼겹살을': 5, '구울때': 3, '중요한': 10, '있지': 9}
◻ TFI-DIF Vectorizer()
◽특성 : 실수(float) 인코딩
![[Screenshot_385.png]]

◽ TF (Text Frequency)
- 토큰의 빈도수
◽ DF (Document Frequency) - 토큰이 등장하는 문장의 수
◽ IDF (Inverse DF) - 문장에 자주 등장하는 토큰은 문장 구분시 중요하지 않다.
- 예시) 을,를,이,가,은,는,에게,으로......
◽ N - 확률(평균)을 구하기 위해 전체갯수로 나눠주기 위한것
◽ log - 비선형방식을 선형방식으로 바꾸기위해 로그를 취함
- 로그->지수 변환 ->선형 | 지수->로그 변환 ->선형
- 빈도수가 선형특성을 갖기때문에 토큰문장구할때도 선형방식으로 변환할필요가있음
- 토큰이 문장에 들어가는 분포를 보면 많이 들어가는 토큰과 그렇지 않는 토큰이 지수의 특성을 지니기 때문에 로그변환으로 선형식으로 바꿔줌
🔶훈련함수
◻ fit() :분석만 수행
◻ fit_transform() : 분석하고 인코딩을 동시에 수행
◻ transform : fit()이나 fit_transform으로 이전에 분석된 결과를 기반으로 인코딩만 수행
🔶3. 임베딩(Embedding)
![[Screenshot_411.png]]
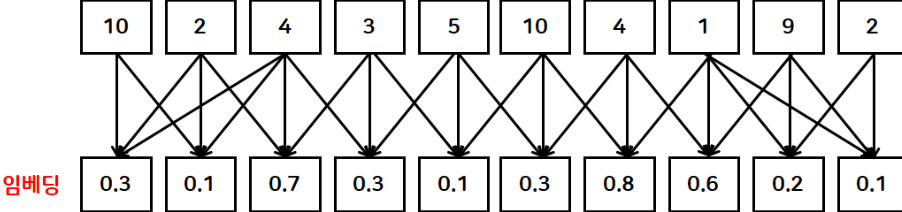
◻개념
- 인코딩된 토큰에 의미를 부여하는 작업
- 단어들 간의 유사성이나 선 후 관계 등을 분석해서 벡터 값(크기,방향) 을 계산하는 작업
◻특성
![[Screenshot_413.png]]
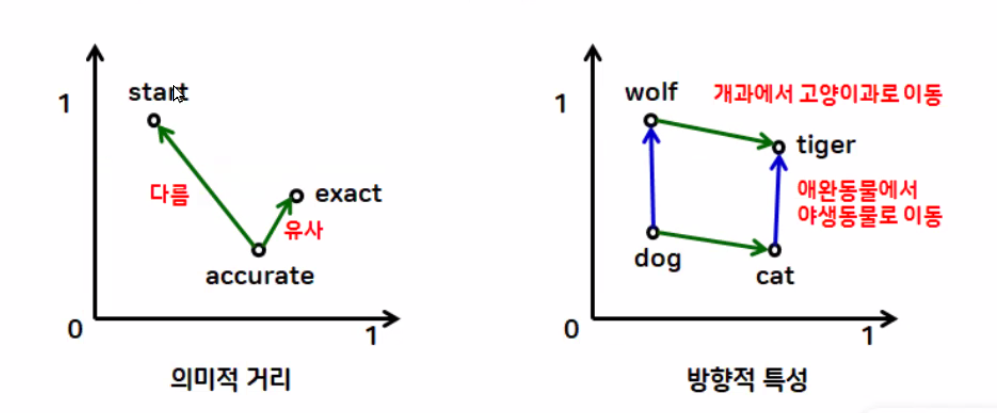
- 거리적특성
- 방향적특성
◻ 맵핑예시

◻ 계산
![[Screenshot_415.png]]
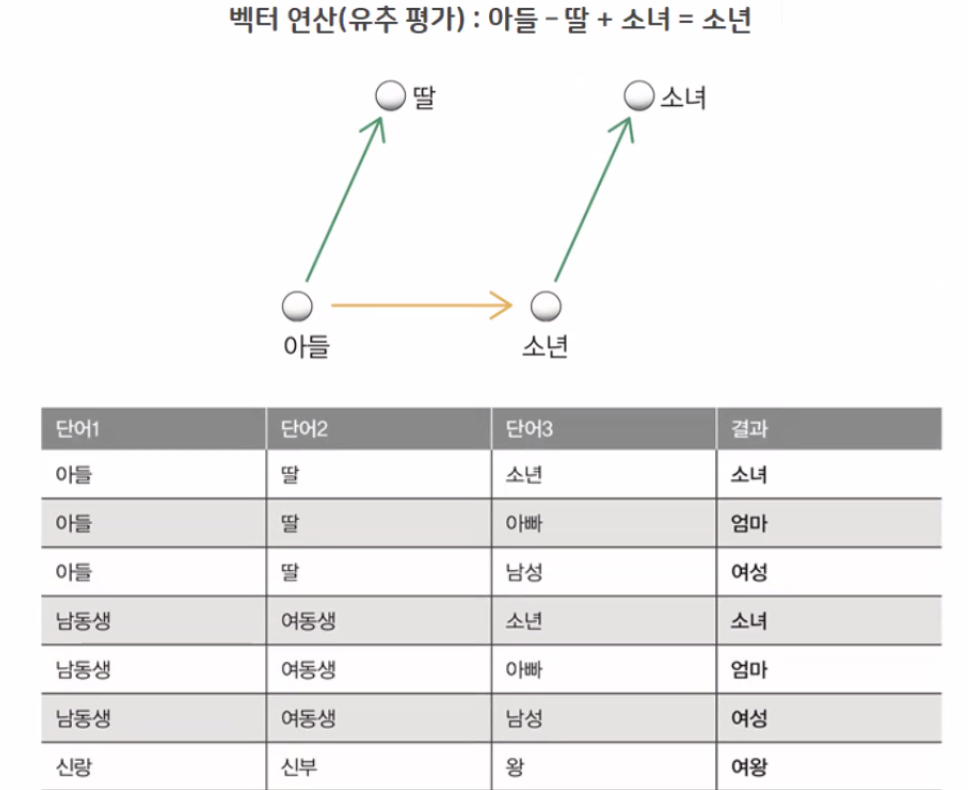
◻ 종류
- 단어 임베딩
- Word2Vec
- 단어들의 지역적 정보를 반영
- GroVe
- 단어들의 전역적 정보를 반영
- FastText
- 내부 단어를 고려
- Word2Vec
- 문장 임베딩
- Doc2Vec
- 문장을 벡터로 변환 (%RAG)
- Doc2Vec
🔶 FastText
◻ 파라미터
◽ sentences
- 토큰 데이터
◽ vector_size - 벡터의 차원수
◽ window - 참고할 근처의 단어수
◽ min_count - 빈도수가 1 이하인 단어는 포함하지 않게 설정
◽ workers - 사용할 CPU스레드수
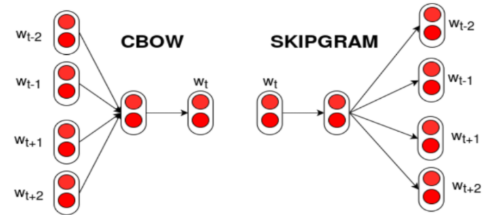
◽ sg - 학습알고리즘(0 : CBOW, 1: Skip-grow)
- CBOW
- 여러개의 단어에서 유사한것을 찾아내는 방식
- Skip-grow
- 하나의단어로 유사한것을 찾아내는 방식
![[Screenshot_386.png]]
- 하나의단어로 유사한것을 찾아내는 방식
- CBOW
실습
데이터
corpus = ["제품을 잘 쓰고 쓰고 있어요", "제품의 디자인이 우수해요", "성능이 우수해요", "제품에 손상이 있어요", "제품 가격이 비싸요", "정말 필요한 제품입니다", "가격이 비싸고 서비스도 엉망이예요", "가격대비 성능이 우수해요", "디자인이 좋아요", "필요없는 기능이 많은듯 해요", "서비스 대응이 나빠요", "제품에 손상이 심해요"] labels = [1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0]
훈련
import numpy as np import gensim from gensim.models import FastText from konlpy.tag import Okt from sklearn.linear_model import LogisticRegression def get_sentence_vector(tokens): # 하나의 문장(토큰 리스트)을 받아서, 해당 문장의 2차원 벡터 표현을 생성 vectors = [fasttext_model.wv[word] for word in tokens if word in fasttext_model.wv] # 만약 문장에 있는 단어가 하나도 모델에 없다면, 0 벡터로 처리 # 있다면 단어 벡터들의 평균을 구해서 문장 전체의 벡터로 사용 return np.mean(vectors, axis=0) if vectors else np.zeros(fasttext_model.vector_size) # 토큰화 okt = Okt() token_texts = [okt.morphs(text) for text in corpus] # 임베딩 fasttext_model = FastText(sentences=token_texts, vector_size=100, window=5, min_count=2, workers=4, sg=1) fasttext_model.wv.most_similar("좋아요") # 훈련준비 X = np.array([get_sentence_vector(tokens) for tokens in token_texts]) y = np.array(labels) print(X) # 훈련 model = LogisticRegression(C=0.01) model.fit(X,y) score = model.score(X,y) print(f'score : {score*100:.2f}')
결과 100.00
예측
# 예측샘플 corpus 선정 X_new1 = ["제품을 안 쓰고 있어요"] X_new2 = ["에라이!! 같네! "] # 토큰화 t1 = okt.morphs(X_new1[0]) t2 = okt.morphs(X_new2[0]) # 임베딩 en_new1 = get_sentence_vector(t1) en_new2 = get_sentence_vector(t2) #예측 pred1 = model.predict([en_new1]) pred2 = model.predict([en_new2]) print(pred1,pred2)
결과 [1][0]
'➕ Data Science > ▹ ML' 카테고리의 다른 글
| 3. 추천시스템 기초 (4) | 2025.06.04 |
|---|---|
| 2. IMDB 영화리뷰 데이터 분류 (2) | 2025.06.02 |
| 9. 보스턴 주택가격 예측 (1) | 2025.05.19 |
| 8. 선형분류 (1) | 2025.05.15 |
| 7. 보스턴주택가격예측 (0) | 2025.05.15 |



